Have you ever wondered if AI assistants like ChatGPT or other large language models (LLMs) know too much? These models are trained on massive piles of data from the internet, books, and pretty much everything else out there. They can answer questions, write essays, and even compose poetry - sounds amazing, right?
When “knowing too much” becomes a risk
Here’s the catch: when an LLM knows too much, it can accidentally spill sensitive information or cause unintended harm. If not carefully managed, these models might “leak” personal details or generate harmful content. Sometimes, it’s not even about someone misusing the system - it’s just how the LLM was designed or the data it was trained on. Let’s dive into this issue and see what’s going on!
Real-World Examples
Lee Luda: The Chatbot That Talked Too Much
Created by Scatter Lab, Lee Luda was designed to chat like a friendly 20-year-old college student. It quickly won users over with its casual, relatable vibe, dishing on everything from gossip to love stories. But there was a problem: it was trained on KakaoTalk conversations without clear consent, which led to it learning and sharing inappropriate or private details. The result? Scatter Lab got slapped with a hefty fine of 103.3 million won (about $92,900) by South Korea’s Personal Information Protection Commission for privacy violations. That’s a costly lesson in being careful with data!

ChatGPT: Talent with a Side of Risk
Developed by OpenAI, ChatGPT is a versatile powerhouse that can handle everything from answering simple questions to writing code or crafting poems. It’s a go-to tool in tons of fields. But it’s not perfect. Sometimes, it produces biased or inappropriate responses, reflecting the biases baked into its training data, like negative stereotypes about certain groups without realizing the consequences. While OpenAI hasn’t faced specific fines yet, they’ve dealt with plenty of criticism from the public and potential legal scrutiny.
GPT-3: Fake News That Sounds Too Real
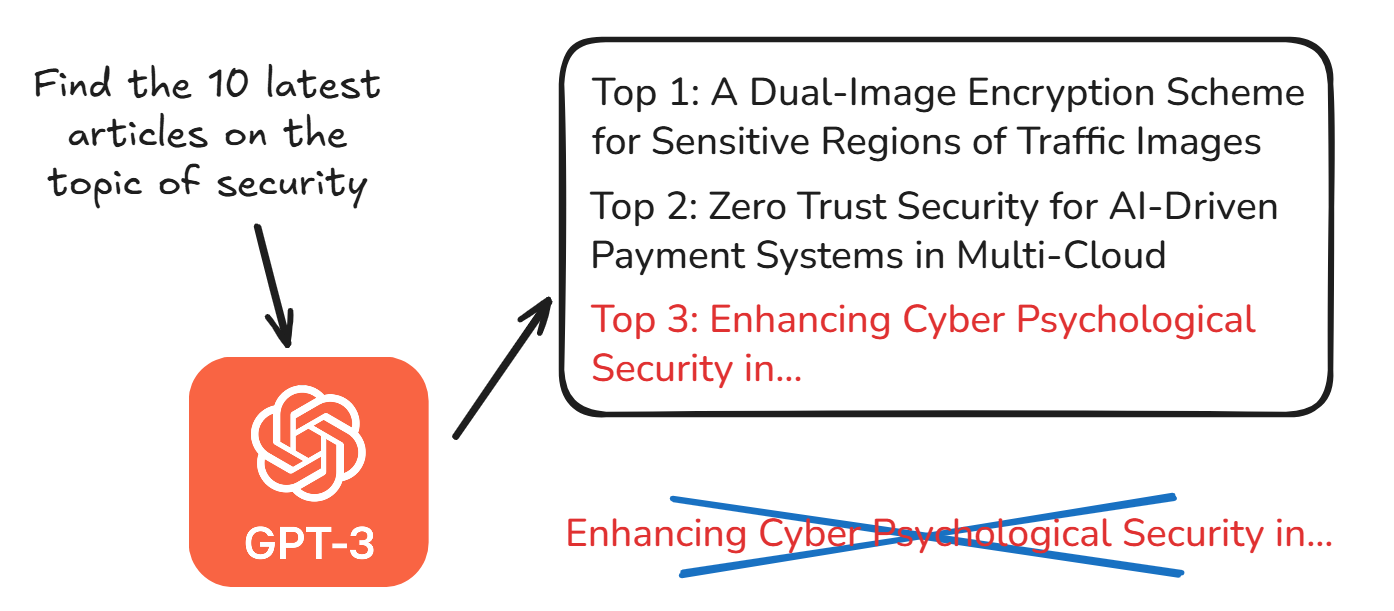
Also from OpenAI, GPT-3 is a beast of a model that can whip up articles, translations, or answers from just a few keywords. But here’s the downside: it can generate fake news or misleading info that sounds incredibly convincing. Since it was trained on datasets that include unverified or inaccurate information, it lacks the ability to fact-check itself. While no specific penalties have been reported, spreading misinformation could lead to serious legal issues or erode trust in OpenAI’s tech.
Wrapping It Up
LLMs are undeniably powerful and bring tons of benefits, but they come with risks. From Lee Luda leaking personal info, to ChatGPT stirring up controversy with biased outputs, to GPT-3 crafting believable fake news, these examples show that “knowing too much” can backfire. So, what’s the fix? Developers need to be pickier about training data, thoroughly test model outputs, and set up guardrails to prevent misuse. As users, we should also be cautious about what we share with AI. When both sides take responsibility, LLMs can be awesome allies instead of risky “know-it-alls” we need to worry about!
References


 Sam Pearcy
Sam Pearcy
https://www.sciencedirect.com/science/article/pii/S2666827024000215