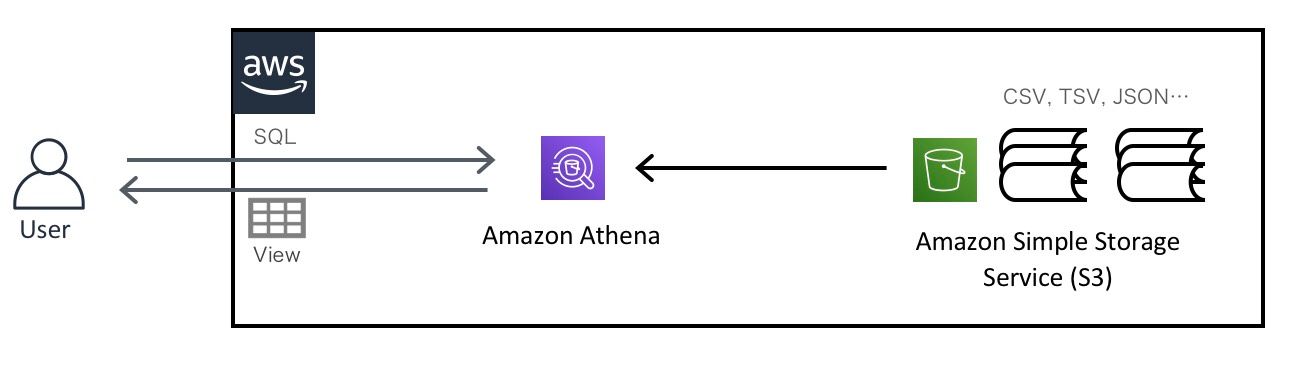
CloudFront Access Logs are a goldmine for understanding CDN traffic patterns, user behavior, and performance metrics. In this post, I’ll walk you through how to:
- Enable CloudFront Access Logs in Parquet format
- Store logs in Amazon S3
- Create an Athena table with projected partitions for efficient querying
All of this is done using Terraform, with reusable modules and configurations.
Step 1: Provision S3 Buckets
We need two buckets:
- One for storing CloudFront logs
- One for Athena query results
resource "aws_s3_bucket" "cloudfront_logs" {
bucket = "${local.prefix}-cloudfront-access-logs"
force_destroy = true
}
resource "aws_s3_bucket" "athena_query_results" {
bucket = "${local.prefix}-athena-query-results"
force_destroy = true
}Step 2: Enable CloudFront Access Logs (Parquet Format)
Using CloudWatch Log Delivery, we configure CloudFront to deliver logs in Parquet format to S3.
resource "aws_cloudwatch_log_delivery_destination" "s3" {
region = "us-east-1"
name = "${local.prefix}-cdn-access-log"
output_format = "parquet"
delivery_destination_configuration {
destination_resource_arn = aws_s3_bucket.cloudfront_logs.arn
}
}Then, we define the delivery sources for both public and private CloudFront distributions:
Define the delivery source for the CloudFront distribution:
resource "aws_cloudwatch_log_delivery" "cdn_public" {
region = "us-east-1"
delivery_source_name = aws_cloudwatch_log_delivery_source.cdn_public.name
delivery_destination_arn = aws_cloudwatch_log_delivery_destination.s3.arn
record_fields = local.cloudfront_log_record_fields
s3_delivery_configuration = local.cloudfront_log_s3_delivery_configuration
}
``Link the source and destination:
resource "aws_cloudwatch_log_delivery" "cdn_public" {
region = "us-east-1"
delivery_source_name = aws_cloudwatch_log_delivery_source.cdn_public.name
delivery_destination_arn = aws_cloudwatch_log_delivery_destination.s3.arn
record_fields = local.cloudfront_log_record_fields
s3_delivery_configuration = local.cloudfront_log_s3_delivery_configuration
}
``
Step 3: Grant Permissions for Log Delivery
Attach an S3 bucket policy to allow CloudWatch to write logs:
resource "aws_s3_bucket_policy" "this" {
bucket = aws_s3_bucket.cloudfront_logs.id
policy = jsonencode({
"Version" : "2012-10-17",
"Statement" : [
{
"Sid" : "AWSLogDeliveryWrite",
"Effect" : "Allow",
"Principal" : {
"Service" : "delivery.logs.amazonaws.com"
},
"Action" : "s3:PutObject",
"Resource" : "${aws_s3_bucket.cloudfront_logs.arn}/*",
"Condition" : {
"StringEquals" : {
"aws:SourceAccount" : "${data.aws_caller_identity.current.account_id}"
},
"ArnLike" : {
"aws:SourceArn" : aws_cloudwatch_log_delivery_source.cdn_public.arn
}
}
}
]
})
}Step 4: Create Athena Database
resource "aws_athena_database" "cloudfront_logs" {
name = "${replace(local.prefix, "-", "_")}_cloudfront_logs_db"
bucket = aws_s3_bucket.athena_query_results.bucket
}
Step 5: Define Athena Table with Projected Partitions
Once logs are delivered in Parquet format, define an Athena table using partition projection.
Example SQL DDL:
CREATE EXTERNAL TABLE cloudfront_logs (
date string,
time string,
x_edge_location string,
sc_bytes bigint,
c_ip string,
cs_method string,
cs_host string,
cs_uri_stem string,
sc_status int,
cs_referer string,
cs_user_agent string,
cs_uri_query string,
cs_cookie string,
x_edge_result_type string,
x_edge_request_id string,
x_host_header string,
cs_protocol string,
cs_bytes bigint,
time_taken double,
x_forwarded_for string,
ssl_protocol string,
ssl_cipher string,
x_edge_response_result_type string,
cs_protocol_version string,
fle_status string,
fle_encrypted_fields string,
c_port int,
time_to_first_byte double,
x_edge_detailed_result_type string,
sc_content_type string,
sc_content_len bigint,
sc_range_start bigint,
sc_range_end bigint,
c_country string,
cache_behavior_path_pattern string
)
PARTITIONED BY (
distributionid string,
year string,
month string,
day string,
hour string
)
STORED AS PARQUET
LOCATION 's3://dev-example-cloudfront-access-logs/AWSLogs/'
TBLPROPERTIES (
'projection.enabled' = 'true',
'projection.distributionid.type' = 'enum',
'projection.distributionid.values' = 'YOUR_DISTRIBUTION_ID',
'projection.year.type' = 'integer',
'projection.year.range' = '2023,2025',
'projection.month.type' = 'integer',
'projection.month.range' = '1,12',
'projection.day.type' = 'integer',
'projection.day.range' = '1,31',
'projection.hour.type' = 'integer',
'projection.hour.range' = '0,23',
'storage.location.template' = 's3://dev-example-cloudfront-access-logs/AWSLogs/${distributionid}/CloudFront/${year}/${month}/${day}/${hour}/logs'
);
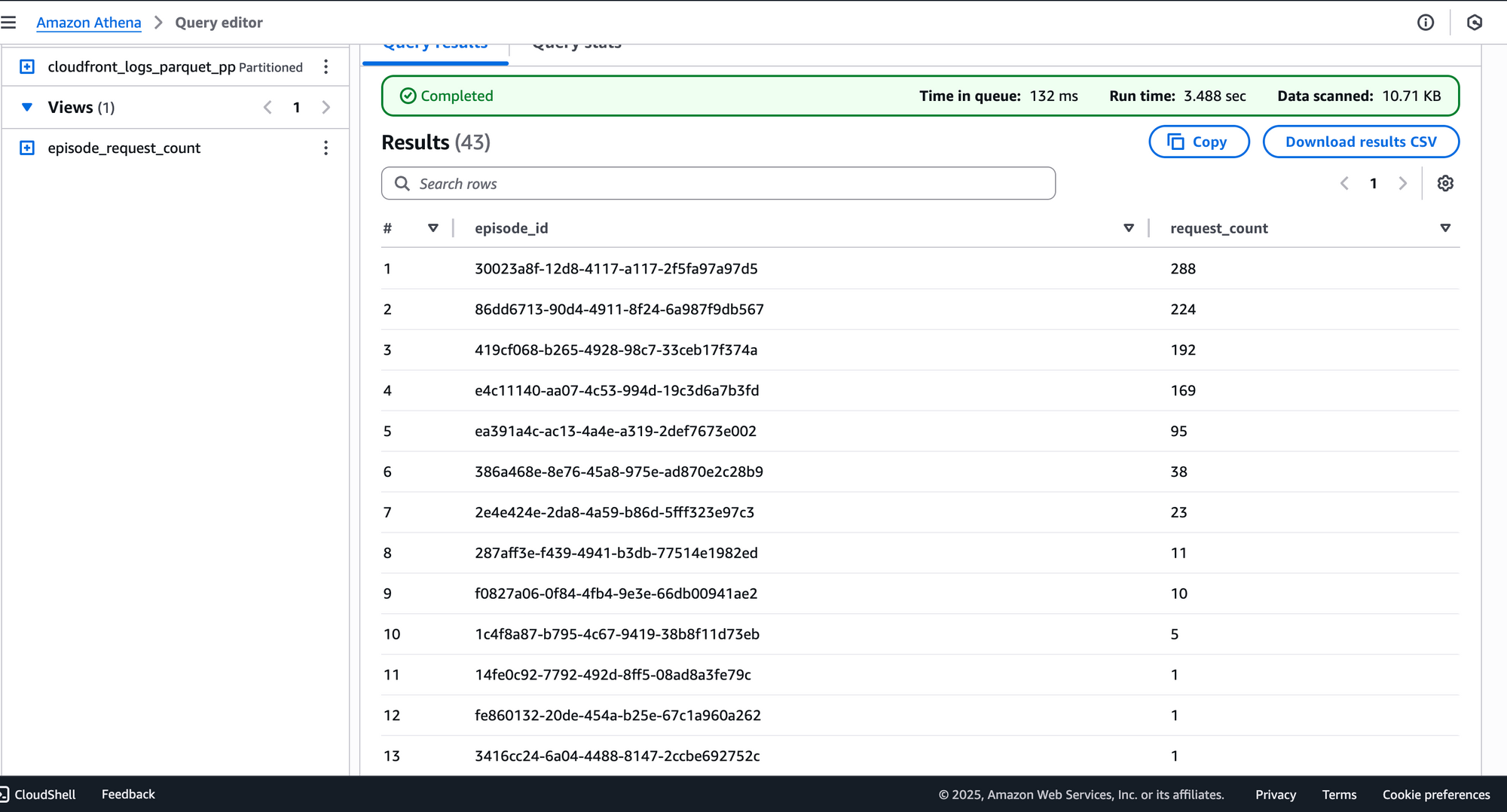
Step 6: Example Athena Query – Count Requests per Episode
Here’s a practical query to count how many times each episode page was requested in October 2025:
SELECT
REGEXP_EXTRACT(cs_uri_stem, '^/episodes/([^/]+)', 1) AS episode_id,
COUNT(*) AS request_count
FROM "dev_bump_cloudfront_logs_db"."cloudfront_logs_parquet_pp"
WHERE
year = 2025
AND month = 10
AND cs_uri_stem LIKE '/episodes/%'
GROUP BY REGEXP_EXTRACT(cs_uri_stem, '^/episodes/([^/]+)', 1)
ORDER BY request_count DESC;What This Does:
- Extracts
episode_idfrom the URI path - Filters logs for October 2025
- Groups and counts requests per episode
- Orders results by popularity
✅ Summary
With this setup, you can:
- Automatically collect CloudFront logs in Parquet format
- Use Athena with projected partitions for fast, cost-effective queries
- Gain insights into user behavior with SQL