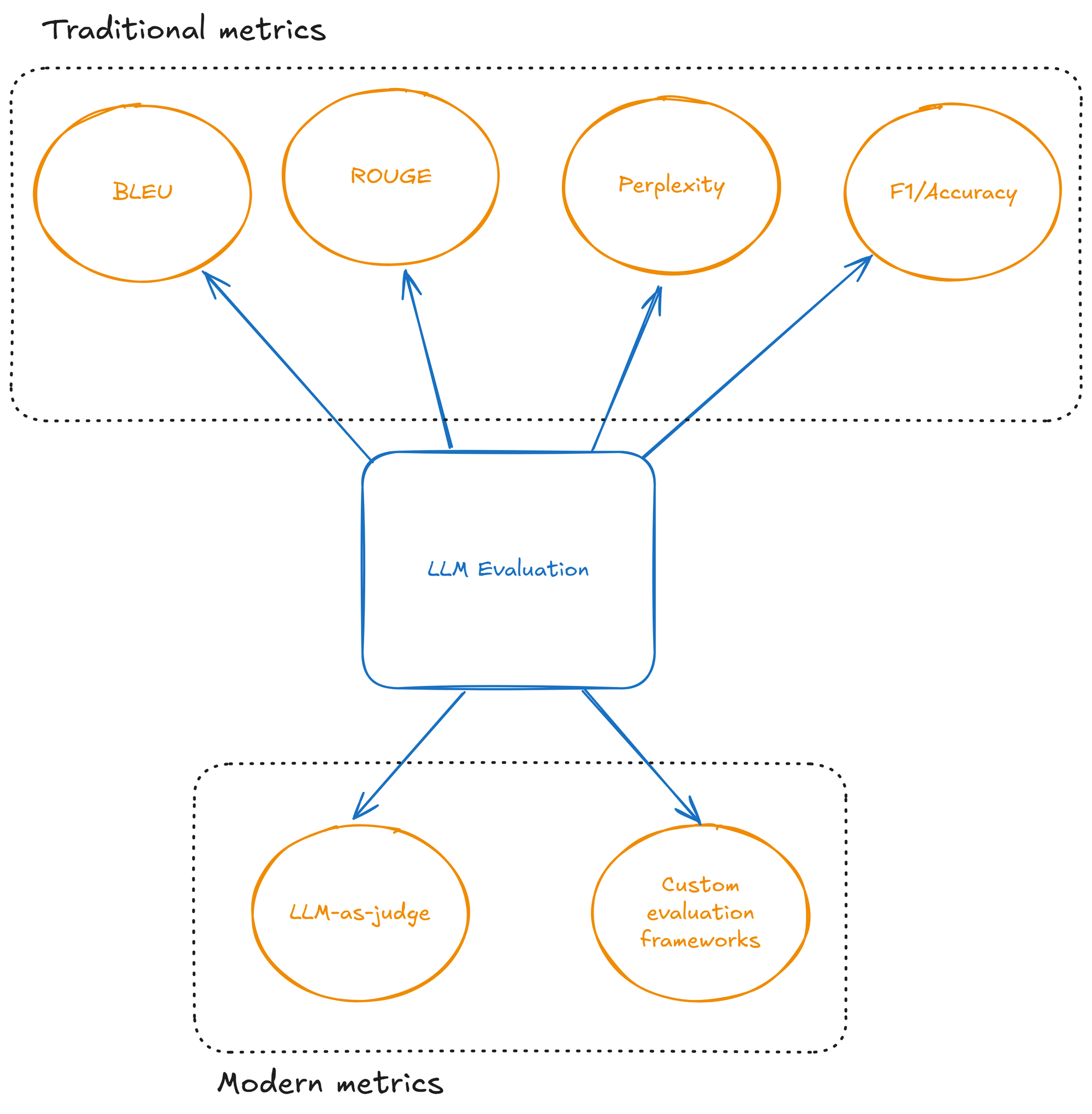
Traditional metrics like BLEU, ROUGE, or perplexity fall short when evaluating modern Large Language Models (LLMs). These metrics, originally designed for machine translation and summarization, cannot capture the nuanced qualities we need from today's AI systems: reasoning, creativity, helpfulness, and safety. This post explores the evaluation approaches, focusing on LLM-as-judge and custom evaluation frameworks.
Classic Metrics
a. BLEU (Bilingual Evaluation Understudy)
BLEU calculates n-gram precision between candidate text and reference text, originally designed for machine translation quality. The range is from 0 to 1, the larger the better.
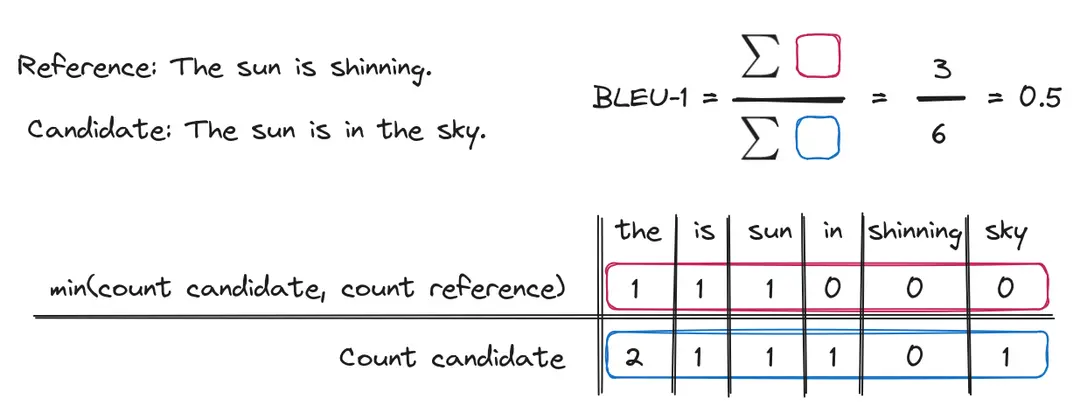
*n-gram precision: how many word sequences (n-grams) in a candidate text match those in a reference text, as a proportion of all n-grams in the candidate text.
Limitation: BLEU rewards word overlap but ignores semantic meaning. Two responses with identical words in different orders can receive similar scores, even if one is nonsensical. Example:
- Reference: "The sun is in the sky."
- Candidate 1: "The sun is in the sky." → Good semantic meaning (BLUE-1 score is 0.66)
- Candidate 2: "Sky the sun in is the." → Poor meaning, but same words (BLUE-1 score is still 0.66)
b. ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
ROUGE focuses on n-grams recall, longest common subsequences, and skip-bigrams between system and reference summaries.
Limitation: ROUGE penalizes valid paraphrasing while rewarding extractive, potentially ungrammatical text that copies source words.
c. Perplexity
Perplexity measures how "surprised" a model is by test data - lower perplexity suggests better prediction of the next token.
Limitation: Perplexity measures fluency, not factual accuracy, relevance, or usefulness. A model can generate highly probable but completely false or harmful text.
d. F1 Score / Accuracy
Classification metrics that measure exact match correctness for tasks like question answering or classification.
Limitation: Binary metrics can't capture partial correctness, alternative valid answers, or responses that are more informative than the reference. Example:
- Ground truth: "William Shakespeare"
- Response 1: "William Shakespeare (1564-1616)" → More informative, but scores 0
- Response 2 = "William Shakespeare" → Exact match, scores 1
- Response 3 = "Shakespeare" → Partially correct, but scores 0
LLM-as-Judge: A Paradigm Shift
a. Core Concept
Using powerful LLMs to evaluate other LLM outputs leverages their understanding of language, context, and quality criteria.
import openai
def evaluate_with_llm_judge(output, criteria):
prompt = f"""
Evaluate the following text based on these criteria:
{criteria}
Text: {output}
Provide a score (1-10) and explanation.
"""
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.contentb. Benefits
- Contextual understanding: Judges grasp nuance and intent
- Flexible criteria: Easily adapt to different evaluation needs
- Explanation capability: Provides reasoning for scores
c. Challenges
- Bias propagation: Judge models have their own biases
- Cost: API calls for evaluation can be expensive
- Consistency: Results may vary between runs
Custom Evaluation Frameworks
Custom evaluation frameworks allow you to measure LLM outputs according to your specific requirements, domain expertise, and business objectives. Unlike generic metrics, these frameworks provide targeted insights into model performance across multiple dimensions that matter for your use case.
a. Multi-Dimensional Assessment
Evaluate outputs across multiple dimensions simultaneously:
- Content Quality: Accuracy, completeness, relevance, clarity
- Structure: Coherence, logical flow, organization
- Style: Tone, reading level, brand voice
- Safety: Bias detection, harmful content filtering, compliance
- Functionality: Task completion, instruction following
b. Weighted Scoring
Not all dimensions matter equally. Assign weights based on priority:
- High-stakes medical advice: 50% accuracy, 10% style
- Creative writing: 40% originality, 20% accuracy
Weights should be adjustable as priorities evolve.
c. Contextual Evaluation
Consider context when judging quality:
- User Context: Technical experts need different responses than general users
- Task Context: Quick lookups require different evaluation than deep research
- Temporal Context: Standards and information freshness change over time
Best Practices
- Iterate on evaluation criteria: Start simple, refine based on failures
- Version control evaluations: Track changes to evaluation logic
- Monitor drift: Regularly validate that evaluations remain relevant
- Balance automation and human review: Use humans for edge cases
- Document decisions: Explain why certain metrics matter
Conclusion
Evaluating LLM outputs requires moving beyond simple metrics to embrace sophisticated, multi-faceted approaches. The key is selecting evaluation methods that align with your specific use case and continuously refining them based on real-world performance.
References