

Large Language Models (LLMs) like GPT-4, Claude, LLaMA, and Mistral have revolutionized natural language processing (NLP), enabling tasks such as text generation, summarization, code writing, and question answering. Despite their capabilities, LLMs face critical limitations that hinder their reliability in dynamic, high-stakes, or domain-specific applications:
- Static Knowledge: LLMs are trained on fixed datasets, meaning their knowledge is frozen at the time of training. They cannot incorporate new information, such as recent events or proprietary data, without retraining.
- Hallucinations: LLMs sometimes produce plausible but factually incorrect or fabricated responses, especially when queried on niche or recent topics.
- Context Limitations: LLMs rely on a finite context window, restricting their ability to process large volumes of external data during inference.
- Lack of Domain Specificity: General-purpose LLMs may struggle with specialized domains (e.g., medical, legal, or enterprise-specific knowledge) unless fine-tuned, which is resource-intensive.
Retrieval-Augmented Generation (RAG) addresses these challenges by combining the strengths of retrieval-based systems (which fetch relevant external information) with generative models (which produce coherent, contextually appropriate responses). This hybrid approach results in AI systems that are more accurate, up-to-date, and adaptable to specific domains, making RAG a cornerstone of modern NLP applications.
This article provides a detailed exploration of RAG, covering its mechanics, benefits, use cases, implementation, challenges, advanced techniques, and future directions. Whether you're a developer, researcher, or business leader, this guide will equip you with the knowledge to leverage RAG effectively.
What is Retrieval-Augmented Generation (RAG)?
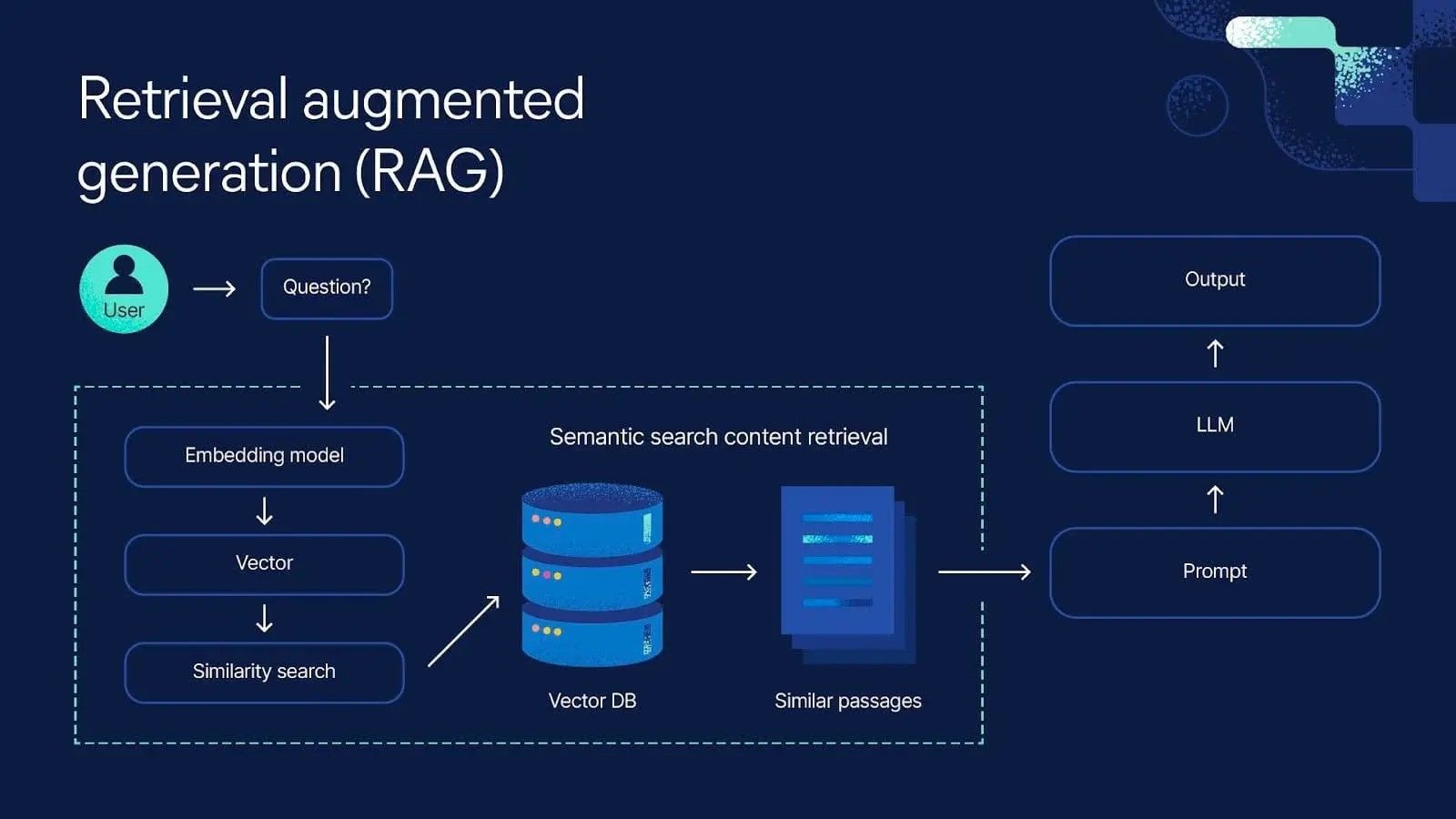
RAG is a technique that enhances LLMs by integrating external knowledge retrieval into the response generation process. Instead of relying solely on the model’s pre-trained knowledge, RAG retrieves relevant documents from an external knowledge base and uses them as context to generate informed, accurate responses.
Core Workflow
The RAG process can be broken down into the following steps:
- User Submits a Query: The user inputs a question or prompt (e.g., "What are the latest treatments for Parkinson’s disease?").
- Retrieval Phase: A retriever queries an external knowledge base (e.g., a vector database, search engine, or document store) to find relevant documents.
- Document Selection: The retriever ranks and selects the top-k most relevant documents based on semantic or keyword similarity to the query.
- Context Integration: The retrieved documents are combined with the user’s query and passed to the LLM as context.
- Generation Phase: The LLM generates a response, leveraging both the query and the retrieved documents to ensure accuracy and relevance.
- Response Delivery: The system returns the final answer to the user, often with citations or references to the retrieved documents for transparency.
Conceptual Architecture
User Query → [Retriever] → Top-k Relevant Documents → [LLM Generator] → Final Answer
Key Components
- Retriever: A search mechanism (e.g., semantic search with vector embeddings or keyword-based search like BM25) that identifies relevant documents.
- Knowledge Base: A repository of documents (e.g., PDFs, web pages, internal wikis, or scientific papers) indexed for efficient retrieval.
- LLM Generator: A language model (e.g., GPT-4, LLaMA, or T5) that synthesizes the query and retrieved context into a coherent response.
- Orchestration Layer: Software that coordinates retrieval and generation, often implemented using frameworks like LangChain, Haystack, or LlamaIndex.
How RAG Differs from Traditional LLMs
- Traditional LLMs: Generate responses based solely on pre-trained knowledge, which may be outdated or incomplete.
- RAG: Dynamically retrieves external information, enabling real-time updates and domain-specific responses without retraining.
- Fine-Tuning: An alternative to RAG, fine-tuning updates an LLM’s weights with new data but is computationally expensive and less flexible. RAG, by contrast, updates the knowledge base independently.
Why Does RAG Matter?
RAG addresses critical pain points in LLM applications, making it a transformative approach for both enterprise and research use cases. Below are the primary reasons RAG is essential:
1. Overcoming Knowledge Cutoff
LLMs are trained on data up to a specific point (e.g., GPT-4’s data cutoff might be late 2023). They cannot access new information, such as recent news, research papers, or proprietary updates, without external augmentation. RAG solves this by retrieving fresh documents from sources like news APIs, academic databases, or internal repositories, ensuring responses reflect the latest information.
Example: A user asks, “What are the outcomes of the 2025 global climate summit?” A traditional LLM would lack this information, but a RAG system could retrieve news articles or official reports from 2025 to provide an accurate summary.
2. Reducing Hallucinations
Hallucinations occur when LLMs generate plausible but incorrect information due to gaps in their training data. By grounding responses in retrieved documents, RAG minimizes this risk, as the LLM can cross-reference factual sources.
Example: If asked, “What is the capital of Wakanda?” a traditional LLM might invent an answer. A RAG system would retrieve documents indicating Wakanda is a fictional country from Marvel, avoiding fabrication.
3. Enabling Personalization and Domain Adaptation
RAG allows LLMs to leverage private or proprietary data without retraining. This is crucial for organizations with sensitive or specialized information, such as corporate policies, medical records, or legal contracts.
Example: A law firm’s AI assistant can use RAG to retrieve case law or internal memos, tailoring responses to the firm’s specific needs without exposing data to public training datasets.
4. Efficient Knowledge Integration
Fine-tuning an LLM on new data is resource-intensive, requiring significant computational power and expertise. RAG bypasses this by updating the knowledge base independently, allowing seamless integration of new information.
Example: A tech company can add new product manuals to its knowledge base, and the RAG system will immediately incorporate them into customer support responses.
5. Scalability and Cost-Effectiveness
RAG is modular, enabling organizations to scale their knowledge base without modifying the LLM. This reduces costs compared to retraining or deploying multiple fine-tuned models.
Example: A university can maintain a growing repository of research papers, and the RAG system will scale to handle queries across disciplines without additional LLM training.
Detailed Use Cases of RAG
RAG’s versatility makes it applicable across industries. Below are expanded examples with practical scenarios and implementation notes.
1. Enterprise Knowledge Assistant
Scenario: A multinational corporation with thousands of internal documents (HR policies, technical manuals, financial reports) needs an AI assistant to help employees find information quickly.
- Without RAG: An LLM might provide generic or outdated answers, as it wasn’t trained on the company’s proprietary data.
- With RAG:
- Query: “What is the current process for requesting remote work?”
- Retriever: Searches an internal document repository (e.g., SharePoint indexed in Pinecone) and retrieves the latest HR policy.
- LLM: Generates a clear, concise response: “To request remote work, submit Form RW-2025 via the HR portal, including a justification and manager approval, as per the updated policy effective January 2025.”
- Implementation: Use LangChain with a vector store like Chroma to index internal PDFs. Integrate with a corporate API for real-time document updates.
2. Scientific Research Assistant
Scenario: A medical researcher needs to stay updated on the latest findings in a niche field, such as the role of gut microbiota in neurodegenerative diseases.
- Without RAG: The LLM provides a general summary based on outdated training data, missing recent breakthroughs.
- With RAG:
- Query: “What is the current understanding of the relationship between gut microbiota and Parkinson’s disease?”
- Retriever: Queries PubMed or arXiv via a vector database (e.g., FAISS) and retrieves recent peer-reviewed papers.
- LLM: Synthesizes findings: “Recent studies (e.g., Smith et al., 2024) suggest that gut microbiota dysbiosis may contribute to Parkinson’s disease progression via the gut-brain axis, with specific bacterial strains like Lactobacillus showing protective effects.”
- Implementation: Use Haystack with ElasticSearch for full-text search and FAISS for semantic search. Preprocess papers to extract abstracts and key findings for efficient retrieval.
3. Customer Support Chatbot
Scenario: An e-commerce company frequently updates its product catalog and support documentation, requiring a chatbot to provide accurate troubleshooting and product information.
- Without RAG: The chatbot suggests outdated solutions or fails to address new product features.
- With RAG:
- Query: “How do I reset my SmartWidget Pro 2025?”
- Retriever: Accesses the latest user manual from the company’s CMS (e.g., indexed in Weaviate).
- LLM: Responds: “To reset your SmartWidget Pro 2025, press and hold the power button for 10 seconds until the LED flashes red, then follow the setup wizard, as outlined in the 2025 user manual.”
- Implementation: Use LlamaIndex to index support tickets and manuals. Integrate with a NestJS backend to handle chatbot queries and retrieval.
4. Educational Tutor
Scenario: A language learning platform needs an AI tutor to explain linguistic concepts, such as metaphors, in multiple languages, including Vietnamese.
- Without RAG: The LLM provides a generic definition of “metaphor” that may lack cultural or linguistic nuance.
- With RAG:
- Query: “What is a metaphor in Vietnamese?”
- Retriever: Pulls Vietnamese linguistic resources or literature textbooks from a knowledge base.
- LLM: Explains: “In Vietnamese, a metaphor (ẩn dụ) is a figure of speech where one thing is described as another to imply similarity, without using ‘như’ or ‘tựa như.’ For example, ‘Mắt em là biển xanh’ (Her eyes are the blue sea) suggests depth and beauty.”
- Implementation: Use multilingual embeddings (e.g., XLM-RoBERTa) to index Vietnamese documents. Deploy with LangChain for cross-lingual retrieval.
5. Legal and Compliance Advisor
Scenario: A financial institution needs an AI to answer regulatory compliance questions based on the latest laws and internal policies.
- Without RAG: The LLM might misinterpret regulations or provide outdated advice.
- With RAG:
- Query: “What are the 2025 AML requirements for crypto exchanges in Vietnam?”
- Retriever: Queries a database of Vietnamese financial regulations and internal compliance documents.
- LLM: Responds: “Under Vietnam’s 2025 AML regulations, crypto exchanges must implement KYC procedures, report transactions exceeding 300 million VND, and maintain records for 7 years, as per Decree 123/2025.”
- Implementation: Use Pinecone for semantic search and BM25 for keyword-based retrieval of legal texts. Ensure data privacy with encrypted indexing.
How Does RAG Work in Practice?
Detailed Components of a RAG System
- Retriever
- Function: Searches the knowledge base to find documents relevant to the query.
- Types:
- Semantic Search: Uses vector embeddings to capture meaning (e.g., Pinecone, Weaviate, FAISS, Chroma). Embeddings are generated by models like OpenAI’s text-embedding-ada-002 or Hugging Face’s sentence-transformers.
- Keyword-Based Search: Matches query terms to document content (e.g., BM25, ElasticSearch). Useful for precise, term-specific queries.
- Hybrid Search: Combines semantic and keyword search for better accuracy.
- Example: For the query “Why is seawater blue?”, a semantic retriever might fetch documents discussing light scattering, while a keyword retriever prioritizes exact matches for “seawater” and “blue.”
- Knowledge Base
- Function: Stores documents in a format optimized for retrieval.
- Formats: PDFs, web pages, Markdown files, internal wikis, JSON records, or database entries.
- Indexing: Documents are preprocessed (e.g., chunked into paragraphs) and converted to embeddings or keyword indices.
- Example: A knowledge base for a tech company might include product manuals, support tickets, and blog posts, indexed in FAISS for semantic search.
- LLM Generator
- Function: Generates the final response by synthesizing the query and retrieved documents.
- Models: Commercial (GPT-4, Claude) or open-source (LLaMA, Mistral, T5).
- Prompt Engineering: The LLM is prompted with a template like: “Using the following context, answer the query: [query]. Context: [documents].”
- Example: For “What MacBooks have AMD GPUs?”, the LLM uses retrieved Apple specs to list models like the MacBook Pro 15-inch (2016–2019).
- RAG Orchestration Layer
- Function: Coordinates retrieval, document ranking, context formatting, and generation.
- Frameworks:
- LangChain: Python-based, supports vector stores and LLM integrations.
- Haystack: Modular, optimized for search and retrieval.
- LlamaIndex: Focuses on indexing and querying structured data.
- Example: LangChain can chain a Pinecone retriever with a GPT-4 generator to answer queries in real time.
Step-by-Step RAG Pipeline (Python / LangChain)
Below is an expanded example of a RAG pipeline using LangChain, FAISS, and OpenAI embeddings. This code assumes you have an OpenAI API key and a pre-indexed FAISS vector store.
from langchain.vectorstores import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
import os
# Set OpenAI API key
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
# Initialize embeddings
embeddings = OpenAIEmbeddings()
# Load pre-indexed FAISS vector store
vector_store = FAISS.load_local("my_faiss_index", embeddings)
# Create retriever with top-k = 5
retriever = vector_store.as_retriever(search_kwargs={"k": 5})
# Define custom prompt template
prompt_template = """
You are an expert assistant. Using the provided context, answer the query accurately and concisely. If the context is insufficient, say so and provide a general answer. Cite the source if possible.
Query: {query}
Context: {context}
Answer:
"""
prompt = PromptTemplate(template=prompt_template, input_variables=["query", "context"])
# Initialize LLM
llm = ChatOpenAI(model_name="gpt-4", temperature=0.7)
# Create RetrievalQA chain
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # Passes all documents in one prompt
retriever=retriever,
return_source_documents=True, # Returns retrieved documents
chain_type_kwargs={"prompt": prompt}
)
# Run query
query = "How do I reset the SmartWidget Pro 2025?"
result = qa_chain({"query": query})
# Print answer and sources
print("Answer:", result["result"])
print("Sources:", [doc.metadata["source"] for doc in result["source_documents"]])
Explanation:
- Embeddings: OpenAI’s embeddings convert documents and queries into vectors for semantic search.
- Retriever: FAISS retrieves the top 5 documents based on cosine similarity.
- Prompt Template: Ensures the LLM uses the context effectively and cites sources.
- Chain Type: “Stuff” combines all documents into one prompt; alternatives like “map_reduce” process documents individually for large contexts.
Building the Knowledge Base
To create the FAISS index used above:
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Load documents (e.g., PDFs)
loader = PyPDFLoader("smartwidget_manual.pdf")
documents = loader.load()
# Split into chunks (500 characters, 50 overlap)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
# Create FAISS index
vector_store = FAISS.from_documents(chunks, embeddings)
vector_store.save_local("my_faiss_index")
Notes:
- Chunking: Smaller chunks improve retrieval precision but increase indexing overhead.
- Metadata: Store source information (e.g., file name, page number) for traceability.
Design Considerations for RAG Systems
Building an effective RAG system requires careful planning. Below are key considerations with detailed guidance:
-
Document Chunking
- Why: Documents must be split into manageable units (e.g., paragraphs, sections) for retrieval.
- Strategies:
- Fixed-size: Split by character or token count (e.g., 500 characters).
- Semantic: Split by headings, paragraphs, or sentences to preserve meaning.
- Overlap: Add 10–20% overlap between chunks to avoid splitting context.
- Example: A 100-page PDF manual might be chunked into 500-word sections with 50-word overlap.
-
Embedding Quality
- Why: Embeddings determine how well the retriever matches queries to documents.
- Models:
- OpenAI: High-quality but costly (e.g., text-embedding-ada-002).
- Open-Source: Sentence-transformers (e.g., all-MiniLM-L6-v2) are cost-effective and performant.
- Multilingual: XLM-RoBERTa or mBERT for Vietnamese or other non-English languages.
- Tip: Fine-tune embeddings on domain-specific data for better accuracy.
-
Retriever Ranking
- Why: The retriever must prioritize the most relevant documents.
- Techniques:
- Cosine Similarity: Standard for vector-based search.
- Re-ranking: Use a cross-encoder (e.g., ms-marco-MiniLM) to refine initial results.
- Hybrid Search: Combine BM25 (keyword) and vector (semantic) scores.
- Example: For “Why is seawater blue?”, hybrid search might prioritize documents with both “seawater” and semantic matches for “blue.”
-
Context Window Limits
- Why: LLMs have a maximum token limit (e.g., 128K for GPT-4o).
- Solutions:
- Limit top-k documents (e.g., k=3–5).
- Summarize documents before passing to the LLM.
- Use map-reduce chains to process large contexts iteratively.
- Tip: Monitor token usage with libraries like
tiktoken.
-
Latency
- Why: Retrieval and generation add overhead, impacting response time.
- Optimizations:
- Cache frequent queries in Redis or Memcached.
- Use efficient vector stores (e.g., FAISS on GPU).
- Parallelize retrieval and generation with async APIs.
- Example: A NestJS backend can use
@nestjs/axiosfor async retrieval.
-
Evaluation
- Why: RAG systems must be tested for accuracy, relevance, and user satisfaction.
- Metrics:
- Retrieval: Precision, recall, mean reciprocal rank (MRR).
- Generation: BLEU, ROUGE, or human evaluation for coherence.
- End-to-End: User feedback, task completion rate.
- Tip: Use A/B testing to compare RAG vs. non-RAG responses.
-
Multilingual Support (e.g., Vietnamese)
- Why: Non-English queries require robust handling of language-specific nuances.
- Strategies:
- Use multilingual embeddings (e.g., mBERT, XLM-RoBERTa).
- Index Vietnamese documents with proper tokenization (e.g., VnCoreNLP).
- Train retrievers on Vietnamese corpora for better semantic understanding.
- Example: For “ẩn dụ” (metaphor), retrieve Vietnamese literature texts to provide culturally relevant explanations.
Challenges and Limitations
While RAG is powerful, it faces several challenges that developers must address:
-
High-Quality Retrieval
- Issue: Irrelevant or incomplete documents lead to poor responses.
- Solution: Use hybrid search, re-ranking, and fine-tuned embeddings. Regularly audit the knowledge base for outdated or low-quality content.
-
Knowledge Base Maintenance
- Issue: Keeping documents current and comprehensive is labor-intensive.
- Solution: Automate updates with web crawlers or API integrations (e.g., PubMed, Confluence). Use version control for document changes.
-
Context Window Costs
- Issue: Large contexts increase API costs and latency, especially with commercial LLMs.
- Solution: Compress documents with summarization or use open-source LLMs with larger context windows (e.g., LLaMA-3).
-
Ambiguous Documents
- Issue: LLMs may still hallucinate if retrieved documents are vague or contradictory.
- Solution: Implement document validation and confidence scoring. Prompt the LLM to flag uncertainties.
-
Scalability
- Issue: Large knowledge bases or high query volumes strain resources.
- Solution: Use distributed vector stores (e.g., Pinecone) and load-balanced APIs. Optimize indexing with batch processing.
-
Privacy and Security
- Issue: Proprietary or sensitive data in the knowledge base must be protected.
- Solution: Encrypt documents, use access controls, and deploy on-premises vector stores (e.g., FAISS).
Advanced RAG Techniques
RAG is evolving, with new approaches addressing its limitations and expanding its capabilities. Below are advanced techniques:
-
RAG-Fusion
- Concept: Generates multiple query variations (e.g., rephrased questions) to retrieve a broader set of documents, then ranks them for better coverage.
- Example: For “Why is seawater blue?”, generate variations like “What causes the blue color of oceans?” to retrieve diverse sources.
- Implementation: Use LangChain’s query rewriting module with reciprocal rank fusion.
-
Multi-Hop RAG
- Concept: Performs multiple retrieval steps to answer complex queries requiring reasoning across documents.
- Example: For “How does gut microbiota affect Parkinson’s treatment?”, first retrieve documents on microbiota, then on Parkinson’s therapies, and combine insights.
- Implementation: Use Haystack’s iterative retrieval pipeline.
-
RAG with Reasoning Agents
- Concept: Integrates RAG with agentic workflows, where the system decides when to retrieve, generate, or refine answers.
- Example: An agent might retrieve initial documents, identify gaps, and query additional sources before generating a response.
- Implementation: Use LangGraph or CrewAI for agent orchestration.
-
Self-RAG
- Concept: The LLM evaluates retrieved documents for relevance and decides whether to use them or retrieve more.
- Example: If a document on “seawater color” is outdated, the LLM triggers a new retrieval for recent sources.
- Implementation: Use a custom prompt to instruct the LLM to validate documents.
-
Multimodal RAG
- Concept: Retrieves and processes non-text data (e.g., images, tables) alongside text.
- Example: For “What is the chemical composition of seawater?”, retrieve a table of salinity data and a text description.
- Implementation: Use CLIP embeddings for image retrieval and table parsers like
pandas.
Conclusion
Retrieval-Augmented Generation (RAG) is a transformative approach that makes LLMs more accurate, trustworthy, up-to-date, and domain-specific. By combining retrieval and generation, RAG addresses the limitations of static knowledge, hallucinations, and lack of personalization, enabling applications across industries—from enterprise assistants to scientific research tools to customer support bots.
For developers, RAG offers a modular, scalable, and cost-effective way to build intelligent AI systems. With frameworks like LangChain and vector stores like Pinecone, implementing RAG is more accessible than ever. As the field evolves, advanced techniques like multi-hop RAG, RAG-fusion, and multimodal RAG will push the boundaries of what AI can achieve.
Whether you’re building a file upload system with NestJS, exploring linguistic concepts like Vietnamese metaphors, or researching scientific questions, RAG can enhance your applications with real-time, context-aware intelligence.
Next Steps and Resources
To dive deeper into RAG, consider the following:
- Experiment: Build a RAG pipeline with LangChain and FAISS using the code examples above.
- Explore Frameworks:
- LangChain: General-purpose RAG orchestration.
- Haystack: Search-focused RAG.
- LlamaIndex: Data indexing and querying.
- Vector Stores:
- Learn More:
- Read the original RAG paper: Lewis et al., 2020.
- Watch tutorials on YouTube (e.g., “RAG Explained” by DeepLearning.AI).
- Join communities like the LangChain Discord for support.