
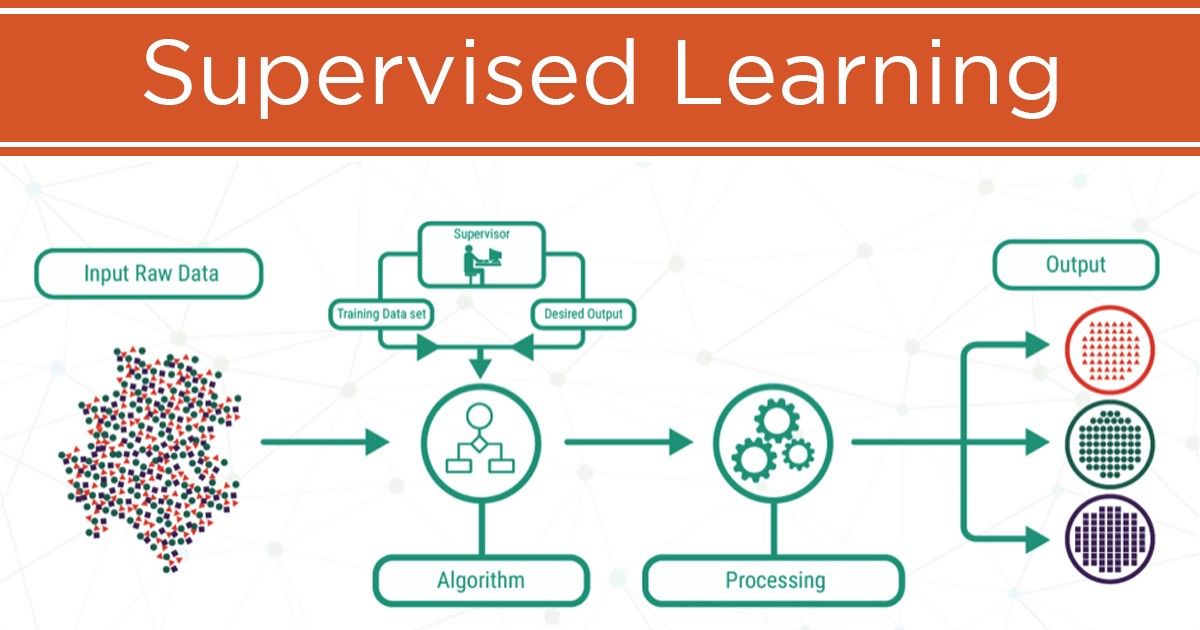
Supervised learning is a machine learning approach that trains AI models using datasets where inputs are paired with human-labeled outputs. The model learns the connections between these inputs and outputs, allowing it to predict accurate results when given new, unlabeled data.
Labeled data includes examples paired with the correct answers. As this data is processed, the algorithm adjusts its weights to properly fit the model. This labeled training explicitly guides the model to recognize the relationships between the features and their corresponding labels.
How supervised learning works
Supervised learning relies on labeled training datasets, where data scientists create inputs paired with corresponding labels. The model learns to apply the correct outputs to new, real-world input data.
During training, the model processes large datasets to identify relationships between inputs and outputs. Its performance is then evaluated using test data to determine training success. Cross-validation involves testing the model on different subsets of the data to ensure reliability.
Gradient descent algorithms, including stochastic gradient descent (SGD), are commonly used to optimize neural networks and other machine learning models. These algorithms use a loss function—a measure of the difference between the model’s predictions and actual results—to evaluate accuracy.
The loss function’s slope, or gradient, guides the optimization process. The algorithm adjusts the model’s parameters by moving down the gradient to minimize the loss, continually refining the model’s settings during training for better performance.
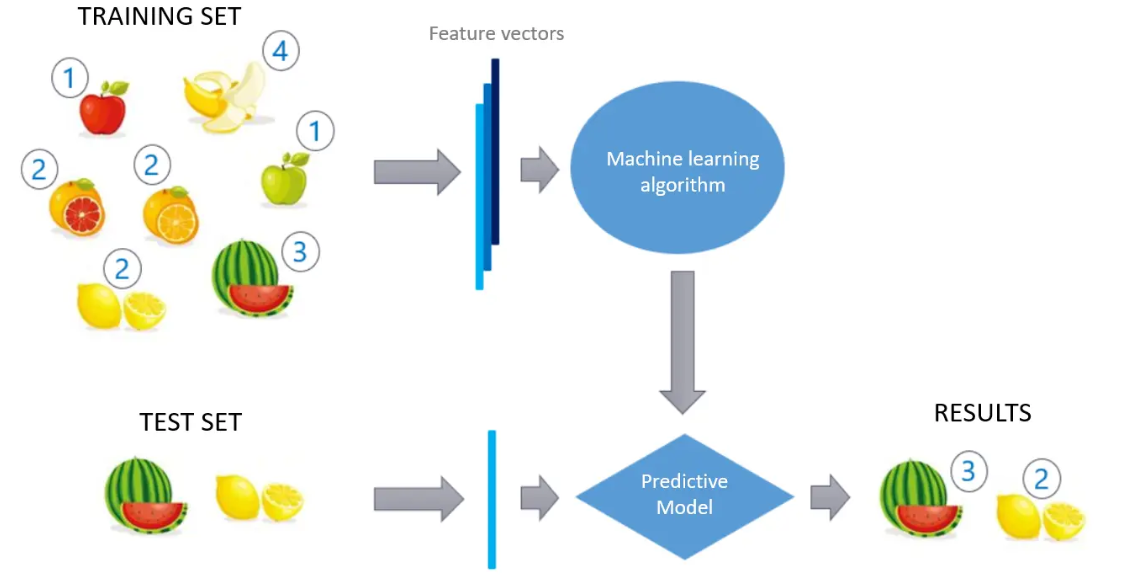
Types of Supervised Learning
1. Regression
Regression is used to predict continuous outcomes like house prices, stock values, or temperatures. These algorithms learn to map input data to a specific numerical value.
Some common regression algorithms include:
- Linear Regression
- Polynomial Regression
- Lasso Regression
- Ridge Regression
2. Classification
Classification is used to predict categorical outcomes, such as whether a customer will make a purchase, if an email is spam, or if a medical image indicates a tumor. These algorithms learn to associate input data with the likelihood of belonging to specific categories or groups.
Some of the most common classification algorithms include:
- Logistic Regression
- Support Vector Machines
- Decision Trees
- Random Forests
- Naive Baye
Applications of Supervised learning
Supervised learning can address a wide range of problems, including:
- Image Classification: Automatically categorizes images into groups like animals, objects, or scenes, supporting tasks such as image search, content moderation, and product recommendations.
- Medical Diagnosis: Assists in identifying diseases by analyzing patient data, including medical images, test results, and medical history.
- Fraud Detection: Detects suspicious patterns in financial transactions to help institutions prevent fraud and protect customers.
- Natural Language Processing (NLP): Powers tasks like sentiment analysis, machine translation, and text summarization, enabling machines to understand and process human language effectively.
Conclusion
Supervised learning is a key area of machine learning that focuses on teaching models to recognize patterns from labeled examples during training. These algorithms enable models to make predictions based on this labeled data. The strength of supervised learning lies in its ability to generalize from training data to new, unseen inputs, making it essential for tasks like image recognition and financial forecasting.
Grasping the different types of supervised learning algorithms and their characteristics is crucial for selecting the right approach to specific problems. As research and development in supervised learning continue, its role in advancing AI-driven solutions will become increasingly important.